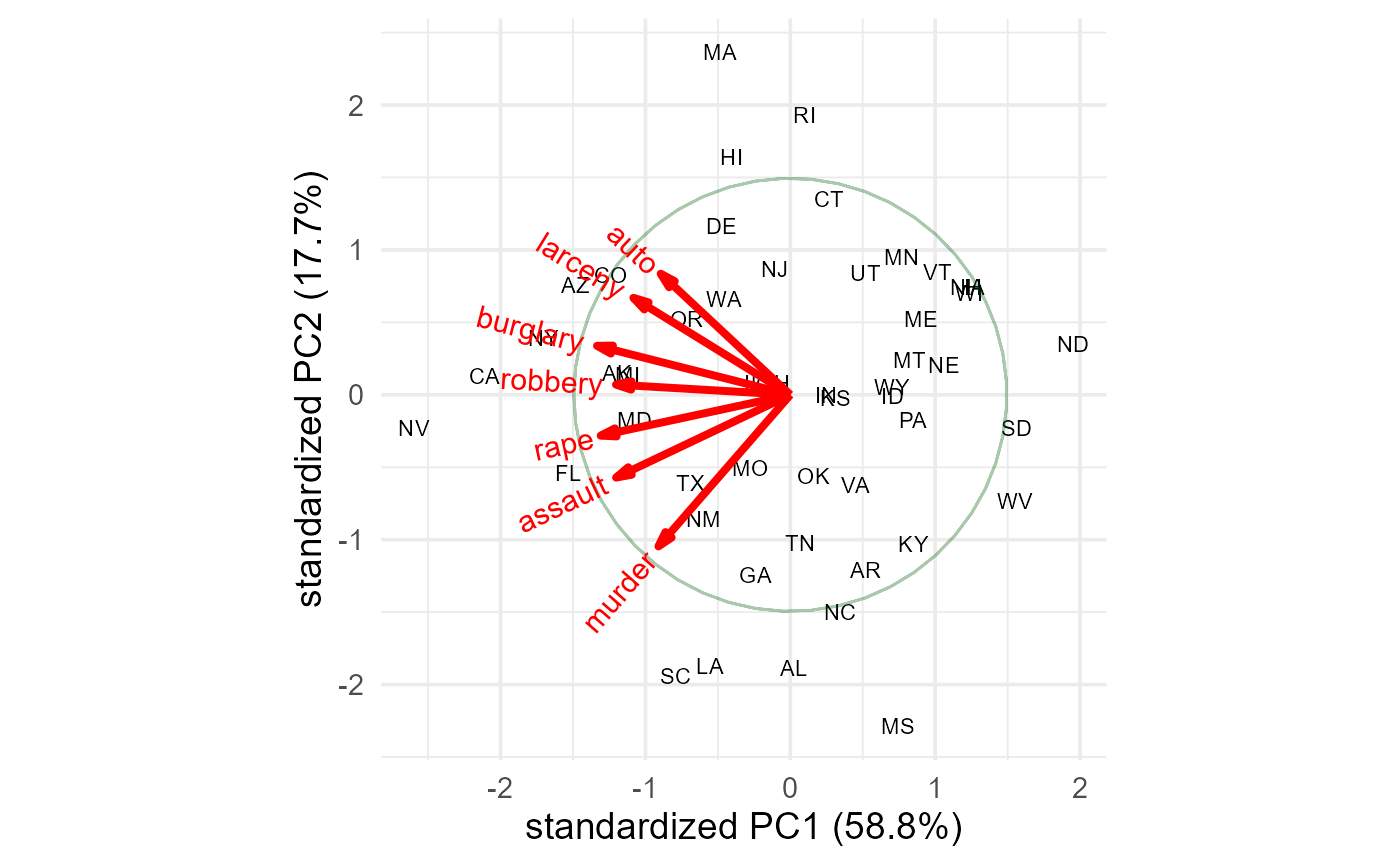
This dataset gives rates of occurrence (per 100,000 people) various serious crimes in each of the 50 U. S. states, originally from the United States Statistical Abstracts (1970). The data were analyzed by John Hartigan (1975) in his book Clustering Algorithms and were later reanalyzed by Friendly (1991).
Usage
data(crime)Format
A data frame with 50 observations on the following 10 variables.
statestate name, a character vector
murdera numeric vector
rapea numeric vector
robberya numeric vector
assaulta numeric vector
burglarya numeric vector
larcenya numeric vector
autoauto thefts, a numeric vector
ststate abbreviation, a character vector
regionregion of the U.S., a factor with levels
NortheastSouthNorth CentralWest
Source
The data are originally from the United States Statistical Abstracts (1970). This dataset also appears in the SAS/Stat Sample library, Getting Started Example for PROC PRINCOMP, https://support.sas.com/documentation/onlinedoc/stat/ex_code/131/princgs.html, from which the current copy was derived.